Ray: A Distributed Execution Framework for AI Applications
This post announces Ray, a framework for efficiently running Python code on clusters and large multi-core machines. The project is open source. You can check out the code and the documentation.
Many AI algorithms are computationally intensive and exhibit complex communication patterns. As a result, many researchers spend most of their time building custom systems to efficiently distribute their code across clusters of machines.
However, the resulting systems are often specific to a single algorithm or class of algorithms. We built Ray to help eliminate a bunch of the redundant engineering effort that is currently repeated over and over for each new algorithm. Our hope is that a few basic primitives can be reused to implement and to efficiently execute a broad range of algorithms and applications.
Simple Parallelization of Existing Code
Ray enables Python functions to be executed remotely with minimal modifications.
With regular Python, when you call a function, the call blocks until the function has been executed. This example would take 8 seconds to execute.
def f():
time.sleep(1)
# Calls to f executed serially.
results = []
for _ in range(8):
result = f()
results.append(result)With Ray, when you call a remote function, the call immediately returns a future (we will refer to these as object IDs). A task is then created, scheduled, and executed somewhere in the cluster. This example would take 1 second to execute.
@ray.remote
def f():
time.sleep(1)
# Tasks executed in parallel.
results = []
for _ in range(8):
result = f.remote()
results.append(result)
results = ray.get(results)Note that the only changes are that we add the @ray.remote decorator to the
function definition, we call the function with f.remote(), and we call
ray.get on the list of object IDs (remember that object IDs are futures) in
order to block until the corresponding tasks have finished executing.
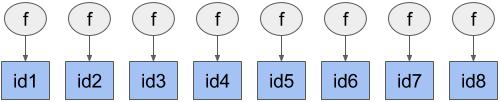
Flexible Encoding of Task Dependencies
In contrast with bulk-synchronous parallel frameworks like MapReduce or Apache Spark, Ray is designed to support AI applications which require fine-grained task dependencies. In contrast with the computation of aggregate statistics of an entire dataset, a training procedure may operate on a small subset of data or on the outputs of a handful of tasks.
Dependencies can be encoded by passing object IDs (which are the outputs of tasks) into other tasks.
import numpy as np
@ray.remote
def aggregate_data(x, y):
return x + y
data = [np.random.normal(size=1000) for i in range(4)]
while len(data) > 1:
intermediate_result = aggregate_data.remote(data[0], data[1])
data = data[2:] + [intermediate_result]
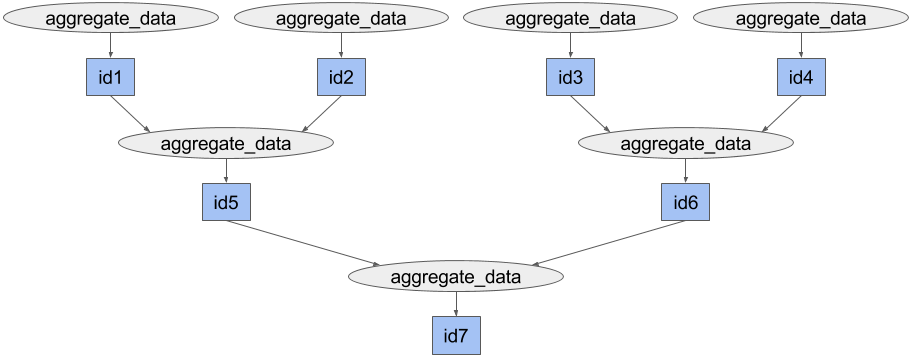
result = ray.get(data[0])By passing the outputs of some calls to aggregate_data into subsequent calls
to aggregate_data, we encode dependencies between these tasks which can be
used by the system to make scheduling decisions and to coordinate the transfer
of objects. Note that when object IDs are passed into remote function calls, the
actual values will be unpacked before the function is executed, so when the
aggregate_data function is executed, x and y will be numpy arrays.
Shared Mutable State with Actors
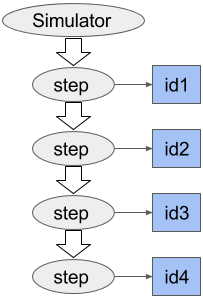
Ray uses actors to share mutable state between tasks. Here is an example in which multiple tasks share the state of an Atari simulator. Each task runs the simulator for several steps picking up where the previous task left off.
import gym
@ray.remote
class Simulator(object):
def __init__(self):
self.env = gym.make("Pong-v0")
self.env.reset()
def step(self, action):
return self.env.step(action)
# Create a simulator, this will start a new worker that will run all
# methods for this actor.
simulator = Simulator.remote()
observations = []
for _ in range(4):
# Take action 0 in the simulator.
observations.append(simulator.step.remote(0))Each call to simulator.step.remote generates a task that is scheduled on the
actor. These tasks mutate the state of the simulator object, and they are
executed one at a time.
Like remote functions, actor methods return object IDs (that is, futures) that
can be passed into other tasks and whose values can be retrieved with ray.get.
Waiting for a Subset of Tasks to Finish
Sometimes when running tasks with variable durations, we don’t want to wait for all of the tasks to finish. Instead, we may wish to wait for half of the tasks to finish or perhaps to use whichever tasks have completed after one second.
@ray.remote
def f():
time.sleep(np.random.uniform(0, 5))
# Launch 10 tasks with variable durations.
results = [f.remote() for _ in range(10)]
# Wait until either five tasks have completed or two seconds have passed and
# return a list of the object IDs whose tasks have finished.
ready_ids, remaining_ids = ray.wait(results, num_returns=5, timeout=2000)In this example ready_ids is a list of object IDs whose corresponding tasks
have finished executing, and remaining_ids is a list of the remaining object
IDs.
This primitive makes it easy to implement other behaviors, for example we may wish to process some tasks in the order that they complete.
# Launch 10 tasks with variable durations.
remaining_ids = [f.remote() for _ in range(10)]
# Process the tasks in the order that they complete.
results = []
while len(remaining_ids) > 0:
ready_ids, remaining_ids = ray.wait(remaining_ids, num_returns=1)
results.append(ray.get(ready_ids[0]))Note that it would be straightforward to modify the above example to adaptively launch new tasks whenever a previous one completes.
Efficient Shared Memory and Serialization with Apache Arrow
Serializing and deserializing data is often a bottleneck in distributed computing. Ray lets worker processes on the same machine access the same objects through shared memory. To facilitate this, Ray uses an in-memory object store on each machine to serve objects.
To illustrate the problem, suppose we create some neural network weights and wish to ship them from one Python process to another.
import numpy as np
weights = {"Variable{}".format(i): np.random.normal(size=5000000)
for i in range(10)} # 2.68sTo ship the neural network weights around, we need to first serialize them into a contiguous blob of bytes. This can be done with standard serialization libraries like pickle.
import pickle
# Serialize the weights with pickle. Then deserialize them.
pickled_weights = pickle.dumps(weights) # 0.986s
new_weights = pickle.loads(pickled_weights) # 0.241sThe time required for deserialization is particularly important because one of the most common patterns in machine learning is to aggregate a large number of values (for example, neural net weights, rollouts, or other values) in a single process, so the deserialization step could happen hundreds of times in a row.
To minimize the time required to deserialize objects in shared memory, we use the Apache Arrow data layout. This allows us to compute offsets into the serialized blob without scanning through the entire blob. In practice, this can translate into deserialization that is several orders of magnitude faster.
# Serialize the weights and copy them into the object store. Then deserialize
# them.
weights_id = ray.put(weights) # 0.525s
new_weights = ray.get(weights_id) # 0.000622sThe call to ray.put serializes the weights using Arrow and copies the result
into the object store’s memory. The call to ray.get then deserializes the
serialized object and constructs a new dictionary of numpy arrays. However, the
underlying arrays backing the numpy arrays live in shared memory and are not
copied into the Python process’s heap.
Note that if the call to ray.get happens from a different machine, the
relevant serialized object will be copied from a machine where it lives to the
machine where it is needed.
In this example, we call ray.put explicitly. However, normally this call would
happen under the hood when a Python object is passed into a remote function or
returned from a remote function.
Feedback is Appreciated
This project is in its early stages. If you try it out, we’d love to hear your thoughts and suggestions.