Key Concepts and Optimizations#
These key concepts will help you design an LLM serving pipeline that meets your service level objectives (SLOs).
1. Key-Value (KV) Caching#
KV caching eliminates redundant computations during text generation:
Without KV Cache:
Recalculate keys and values for entire sequence each time
Extremely inefficient for long sequences
With KV Cache:
Cache computed K and V values for all previous tokens
Only compute K and V for the new token
Reuse cached values for context
2. Continuous Batching#
Continuous batching optimizes throughput by eliminating GPU idle time:
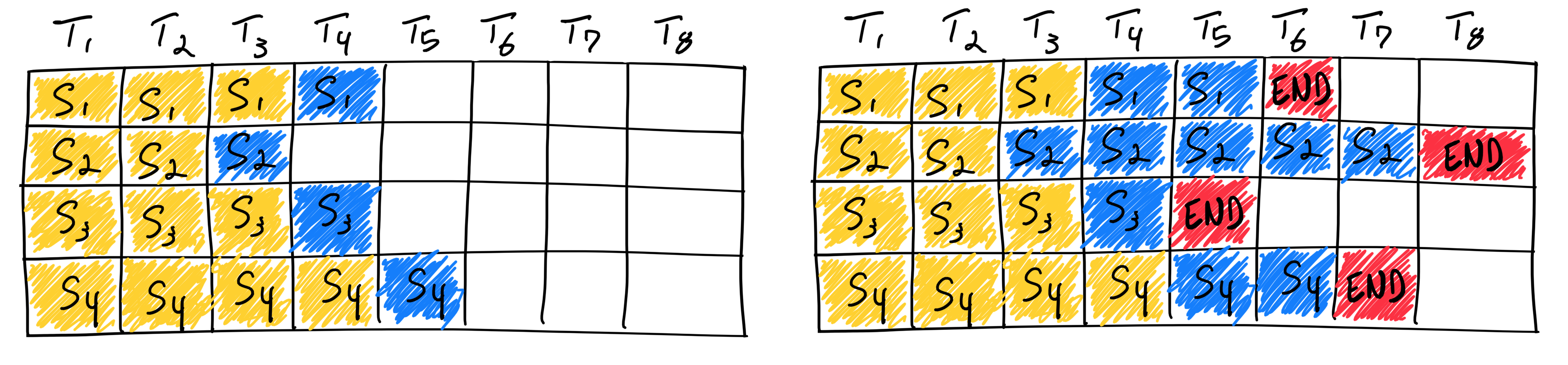
Vanilla Static Batching:
Wait for all requests in batch to complete
Creates idle time when requests finish at different rates
Underutilizes GPU resources
|
|---|
Completing four sequences using static batching. On the first iteration (left), each sequence generates one token (blue) from the prompt tokens (yellow). After several iterations (right), the completed sequences each have different sizes because each emits their end-of-sequence-token (red) at different iterations. Even though sequence 3 finished after two iterations, static batching means that the GPU will be underutilized until the last sequence in the batch finishes generation (in this example, sequence 2 after six iterations). |
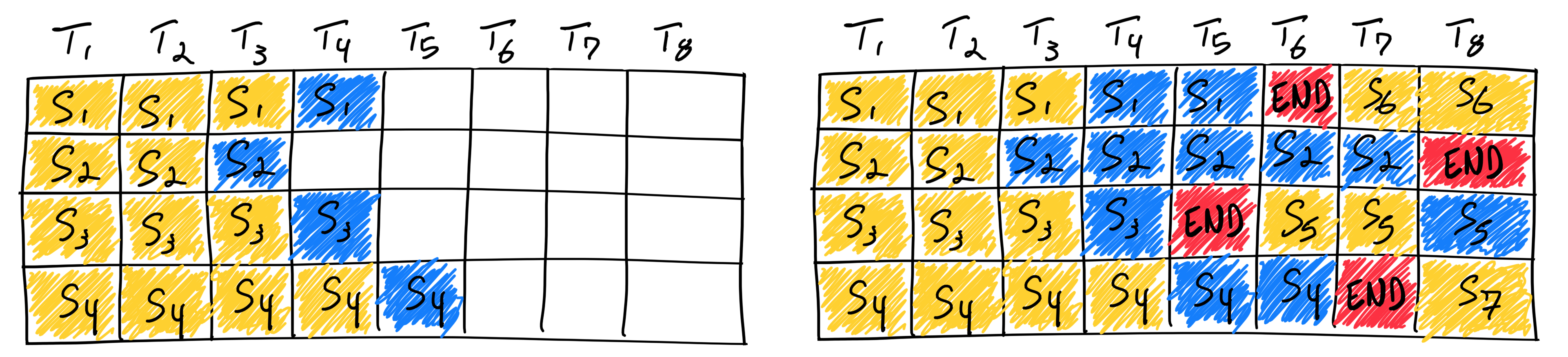
Continuous Batching:
Immediately replace completed requests with new ones
Maintains constant GPU utilization
Increases concurrent user capacity
|
|---|
Completing seven sequences using continuous batching. Left shows the batch after a single iteration, right shows the batch after several iterations. Once a sequence emits an end-of-sequence token, we insert a new sequence in its place (i.e. sequences S5, S6, and S7). This achieves higher GPU utilization since the GPU does not wait for all sequences to complete before starting a new one. |
3. Model parallelization or alternatives#
Large LLMs (>70B) might provides more accurate answers but might not fit entirely on one GPU or one node. You can parallelize your model accross multiple GPUs or nodes to virtually increase your memory resources at the cost of some latency due to communication overhead.
You can also use alternative options such as quantization, distillation, or multi-LoRA adapters to
4. Context Window Considerations#
The context window defines the maximum tokens a model can process:
Context Length |
Use Cases |
Memory Impact |
|---|---|---|
4K-8K tokens |
Q&A, simple chat |
Low KV cache requirements |
32K-128K tokens |
Document analysis, summarization |
Moderate memory usage |
128K+ tokens |
Multi-step agents, complex reasoning |
High memory requirements |
A large context window might provide more accurate answers but also increase the memory pressure and how many requests can be processed concurrently.