📚 01 · Introduction to Ray Train#
In this notebook you’ll learn how to run distributed data-parallel training with PyTorch on an Anyscale cluster using Ray Train V2. You’ll train a ResNet-18 model on MNIST across multiple GPUs, with built-in support for checkpointing, metrics reporting, and distributed orchestration.
What you’ll learn & take away#
Why and when to use Ray Train for distributed training instead of managing PyTorch DDP manually
How to wrap your PyTorch code with
prepare_model()andprepare_data_loader()for multi-GPU executionHow to configure scale with
ScalingConfig(num_workers=..., use_gpu=True)and track outputs withRunConfig(storage_path=...)How to report metrics and save checkpoints using
ray.train.report(...), with best practices for rank-0 checkpointingHow to use Anyscale storage: fast local NVMe vs. persistent cluster/cloud storage
How to inspect training results (metrics DataFrame, checkpoints) and load a checkpointed model for inference with Ray
The entire workflow runs fully distributed from the start: you define your training loop once, and Ray handles orchestration, sharding, and checkpointing across the cluster.
🔎 When to use Ray Train#
Use Ray Train when you face one of the following challenges:
Challenge |
Detail |
Solution |
|---|---|---|
Need to speed up or scale up training |
Training jobs might take a long time to complete, or require a lot of compute |
Ray Train provides a distributed training framework that allows engineers to scale training jobs to multiple GPUs |
Minimize overhead of setting up distributed training |
Engineers need to manage the underlying infrastructure |
Ray Train handles the underlying infrastructure via Ray’s autoscaling |
Achieve observability |
Engineers need to connect to different nodes and GPUs to find the root cause of failures, fetch logs, traces, etc |
Ray Train provides observability via Ray’s dashboard, metrics, and traces that allow engineers to monitor the training job |
Ensure reliable training |
Training jobs can fail due to hardware failures, network issues, or other unexpected events |
Ray Train provides fault tolerance via checkpointing, automatic retries, and the ability to resume training from the last checkpoint |
Avoid significant code rewrite |
Engineers might need to fully rewrite their training loop to support distributed training |
Ray Train provides a suite of integrations with the PyTorch ecosystem, Tree-based methods (XGB, LGBM), and more to minimize the amount of code changes needed |
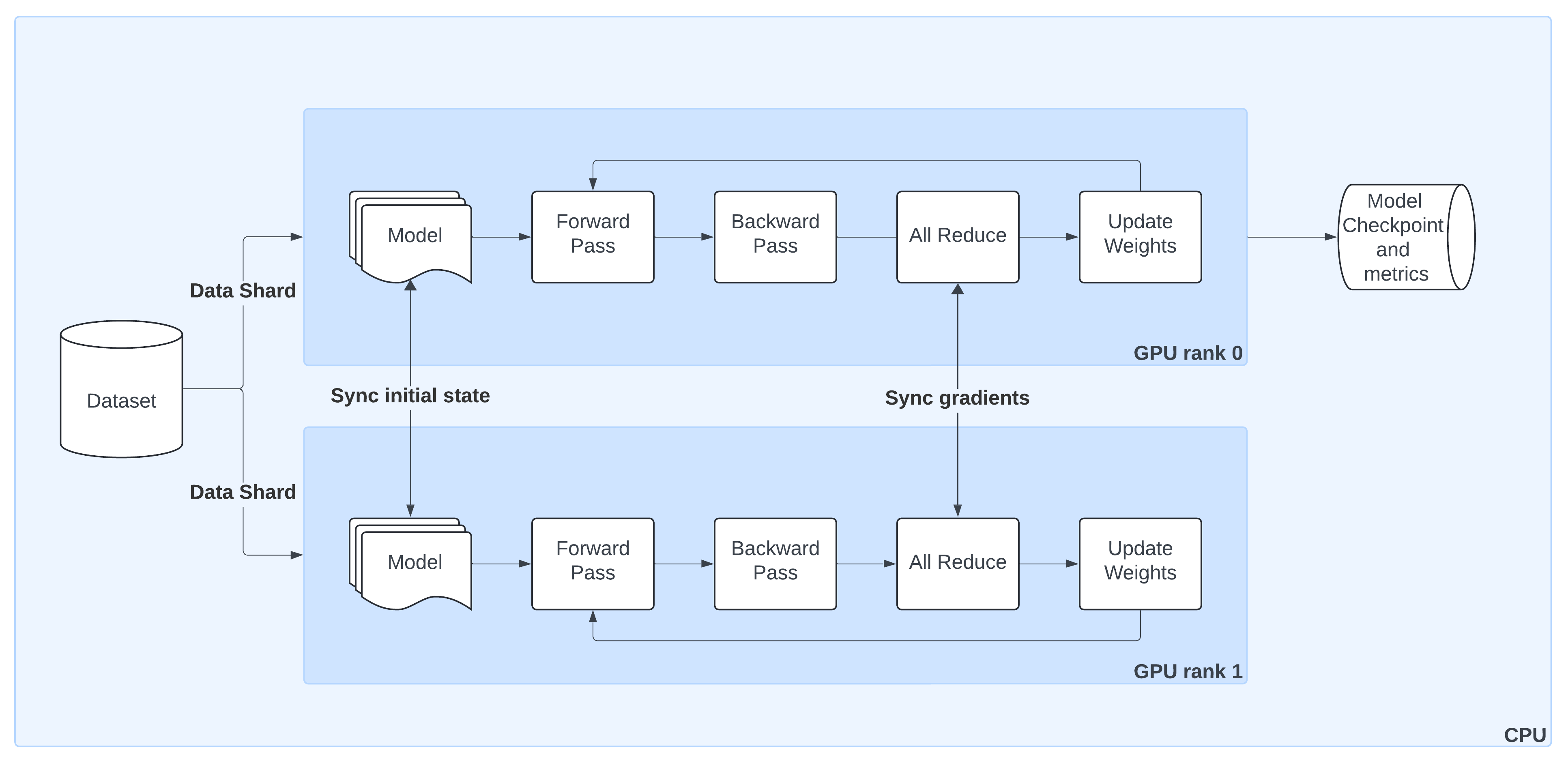
🖥️ How Distributed Data Parallel (DDP) Works#
The diagram above shows the lifecycle of a single training step in PyTorch DistributedDataParallel (DDP) when orchestrated by Ray Train:
Model Replication
The model is initialized on GPU rank 0 and broadcast to all other workers so that each has an identical copy.Sharded Data Loading
The dataset is automatically split into non-overlapping shards. Each worker processes only its shard, ensuring efficient parallelism without duplicate samples.Forward & Backward Passes
Each worker runs a forward pass and computes gradients locally during the backward pass.Gradient Synchronization
Gradients are aggregated across workers via an AllReduce step, ensuring that model updates stay consistent across all GPUs.Weight Updates
Once gradients are synchronized, each worker applies the update, keeping model replicas in sync.Checkpointing & Metrics
By convention, only the rank 0 worker saves checkpoints and logs metrics to persistent storage. This avoids duplication while preserving progress and results.
With Ray Train, you don’t need to manage process groups or samplers manually—utilities like prepare_model() and prepare_data_loader() wrap these details so your code works out of the box in a distributed setting.
|
|---|
Schematic overview of DistributedDataParallel (DDP) training: (1) the model is replicated from the |