04 · Define ResNet-18 Model for MNIST#
Now let’s define the ResNet-18 architecture we’ll use for classification.
torchvision.models.resnet18is preconfigured for 3-channel RGB input and ImageNet classes.Since MNIST digits are 1-channel grayscale images with 10 output classes, we need two adjustments:
Override the first convolution layer (
conv1) to acceptin_channels=1.Set the final layer to output 10 logits, one per digit class (handled by
num_classes=10).
This gives us a ResNet-18 tailored for MNIST while preserving the rest of the architecture.
# 04. Define ResNet-18 Model for MNIST
def build_resnet18():
# Start with a torchvision ResNet-18 backbone
# Set num_classes=10 since MNIST has digits 0–9
model = resnet18(num_classes=10)
# Override the first convolution layer:
# - Default expects 3 channels (RGB images)
# - MNIST is grayscale → only 1 channel
# - Keep kernel size/stride/padding consistent with original ResNet
model.conv1 = torch.nn.Conv2d(
in_channels=1, # input = grayscale
out_channels=64, # number of filters remains the same as original ResNet
kernel_size=(7, 7),
stride=(2, 2),
padding=(3, 3),
bias=False,
)
# Return the customized ResNet-18
return model
Migration roadmap: from standalone PyTorch to PyTorch with Ray Train
The following are the steps to take a regular PyTorch training loop and run it in a fully distributed setup with Ray Train.
- Configure scale and GPUs — decide how many workers and whether each should use a GPU.
- Wrap the model with Ray Train — use
prepare_model()to move the ResNet to the right device and wrap it in DDP automatically. - Wrap the dataset with Ray Train — use
prepare_data_loader()so each worker gets a distinct shard of MNIST, moved to the correct device. - Add metrics & checkpointing — report training loss and save checkpoints with
ray.train.report()from rank-0. - Configure persistent storage — store outputs under
/mnt/cluster_storage/so that results and checkpoints are available across the cluster.
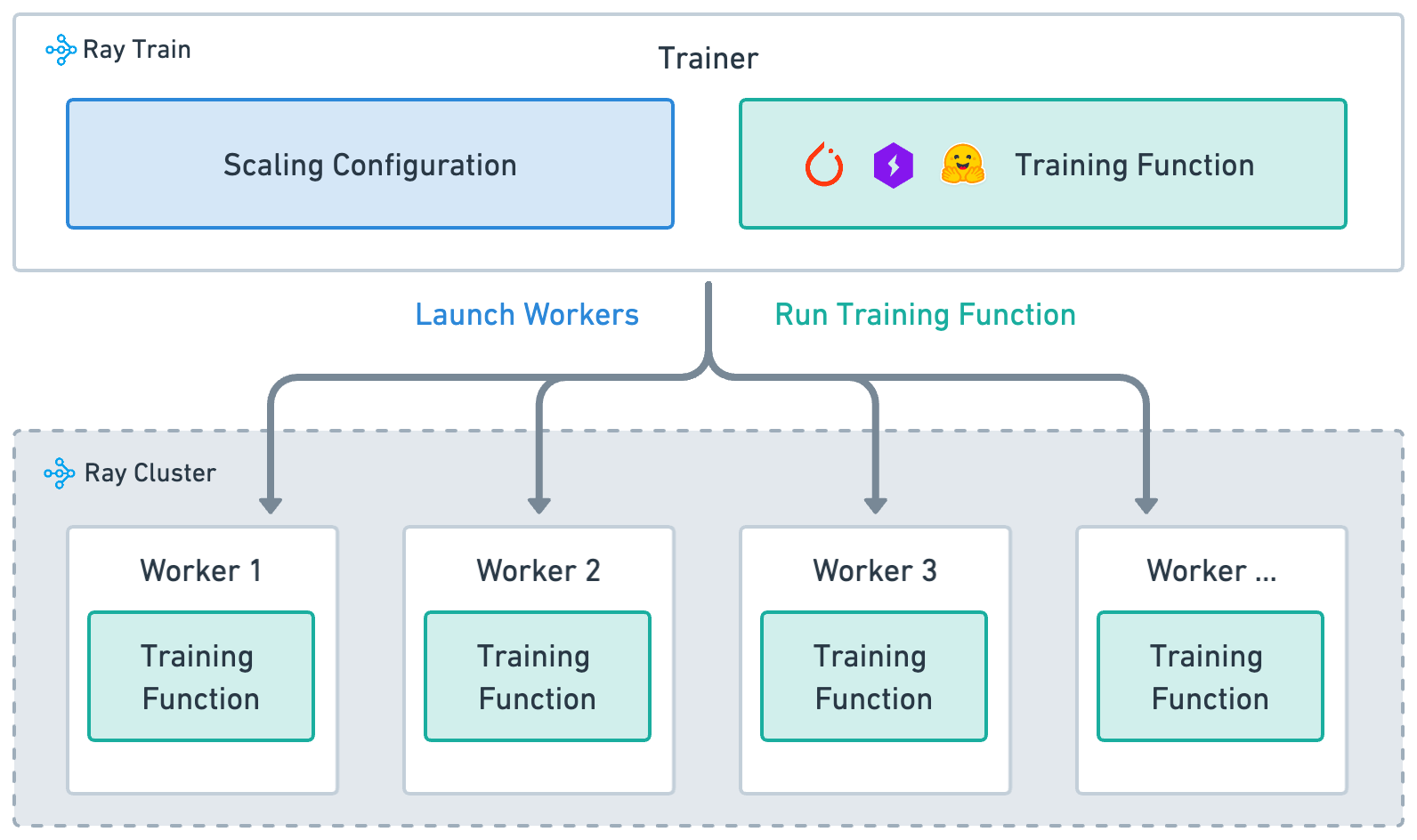
Ray Train is built around four key concepts:
Training function: (implemented above
train_loop_ray_train): A Python function that contains your model training logic.Worker: A process that runs the training function.
Scaling config: specifices number of workers and compute resources (CPUs or GPUs, TPUs).
Trainer: A Python class (Ray Actor) that ties together the training function, workers, and scaling configuration to execute a distributed training job.
|
|---|
High-level architecture of how Ray Train |