Challenges in LLM Serving#
Serving LLMs in production presents several unique challenges that traditional model serving doesn’t face. Let’s explore these challenges and understand why they matter.
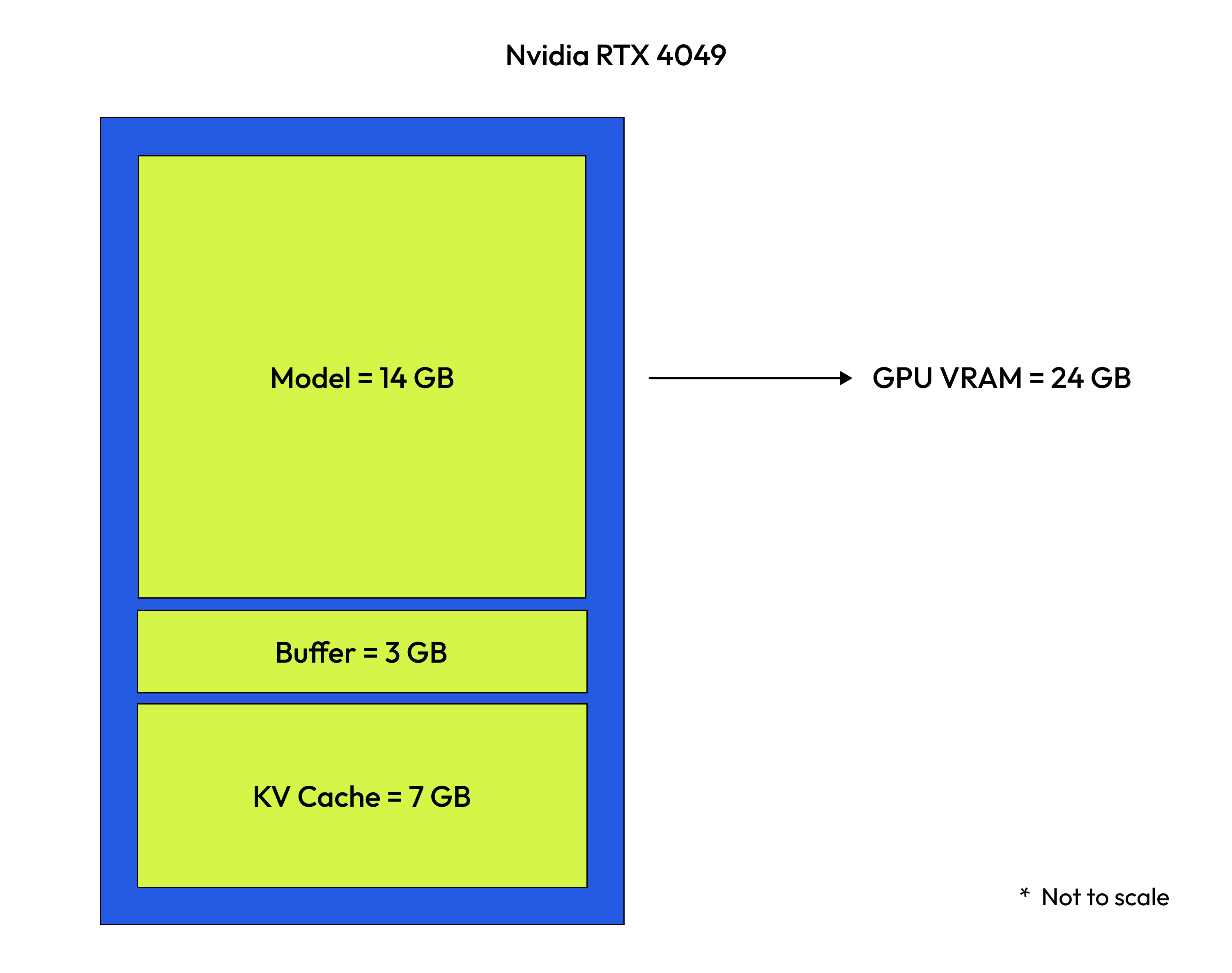
1. Memory Management#
Deploying LLMs is a memory-intensive task. A non-exhaustive list of memory constraints are:
Component |
Description |
Memory Impact |
|---|---|---|
Model Weights |
Model parameters |
7B model ≈ 14GB (FP16) |
KV Cache |
Token representations |
Depends on context length |
Activations |
Temporary buffers |
Varies with batch size |
Example: A 7B parameter model in FP16 precision requires approximately 14GB just for the model weights, not including the KV cache or activations.
You can distribute your deployment on multiple GPUs or nodes. For example you could split the model accross multiple GPUs on a single node or accross multiple GPUs on multiple nodes.
See examples below for examples of different types of deployment:
Single node, single GPU: Deploy a small-sized LLM
Single node, multiple GPU with tensor parallelism: Deploy a medium-sized LLM
Multiple nodes, multiple GPU with tensor and pipeline parallelism: Deploy a large-sized LLM
2. Latency Requirements#
Users expect fast, interactive responses from LLM applications:
Time to First Token (TTFT): How long until the first token appears
Time Per Output Token (TPOT): How long between subsequent tokens
Total Response Time: End-to-end latency
3. Scalability Demands#
Production traffic is unpredictable and bursty:
Traffic spikes during peak hours
Need to scale up quickly during high demand
Scale down to zero during idle periods to save costs
4. Cost Optimization#
GPUs represent significant infrastructure costs:
Maximize hardware utilization
Scale to zero during idle periods
Choose appropriate GPU types for your workload
Why not Kubernetes ?#
You could either use Ray Serve or Kubernetes microservices to solve the challenges above. They are not mutually exclusive, as Ray Serve can run on Kubernetes. The differences are mostly about who does the orchestration and how much abstraction you want from the inference pipeline.
Ray Serve LLM
Python-native orchestration (routing, batching, streaming).
Built-in autoscaling, backpressure, health checks or LLM-optimized routing.
Actor-based sharding across nodes/GPUs.
Easy multi-model serving behind one endpoint.
Kubernetes
Pod = unit per node; multi-node model parallelism needs extra controllers/operators.
Batching/routing/backpressure are DIY (app or sidecars).
Strong platform features (networking, security, quotas), but inference control isn’t built-in.