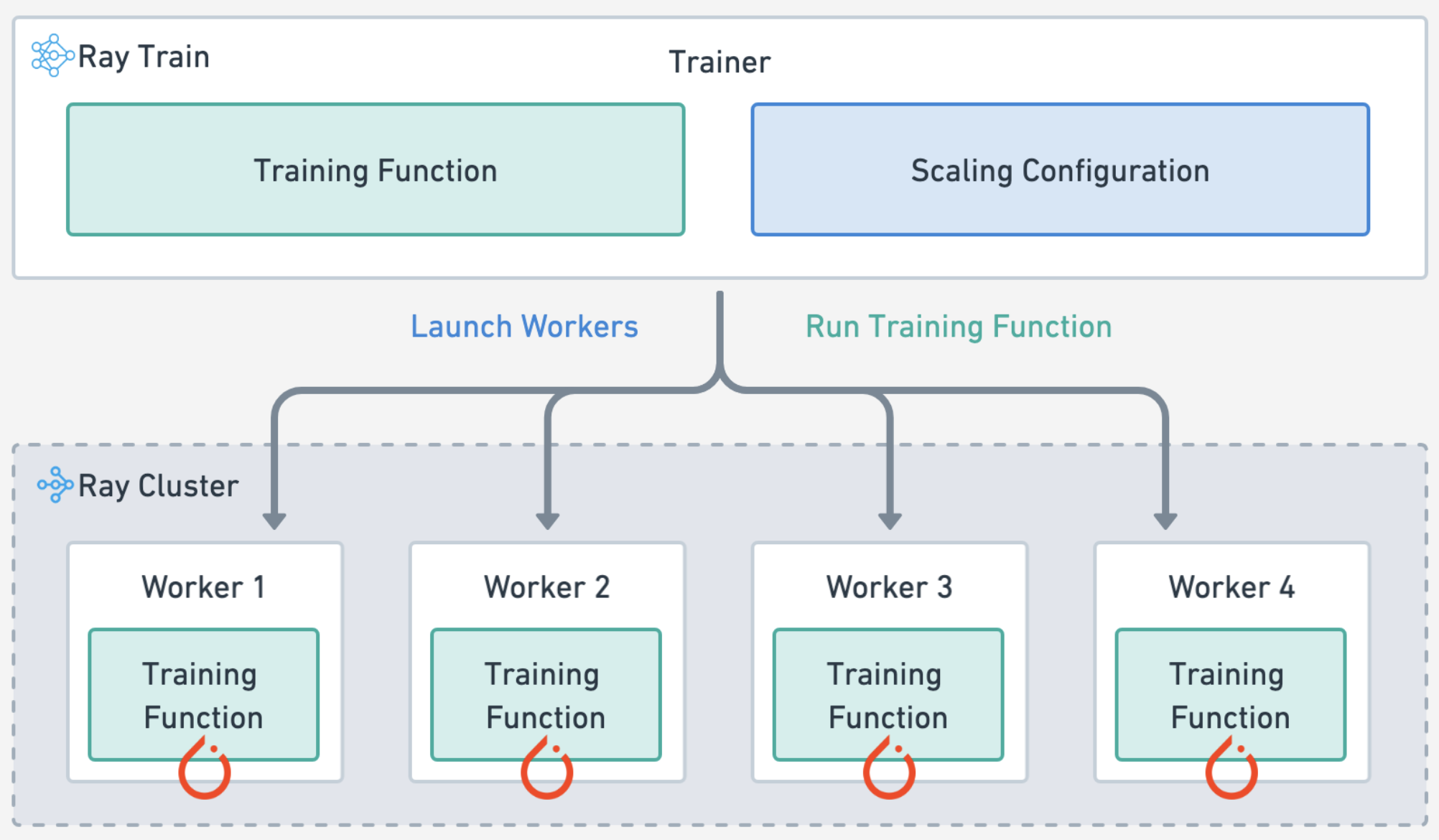
Training#
Define the training workload by specifying the:
experiment and model parameters
compute scaling configuration
forward pass for batches of training and validation data
train loop for each epoch of data and checkpointing
# Train loop config.
experiment_name = "doggos"
train_loop_config = {
"model_registry": model_registry,
"experiment_name": experiment_name,
"embedding_dim": 512,
"hidden_dim": 256,
"dropout_p": 0.3,
"lr": 1e-3,
"lr_factor": 0.8,
"lr_patience": 3,
"num_epochs": 20,
"batch_size": 256,
}
# Scaling config
num_workers = 4
scaling_config = ray.train.ScalingConfig(
num_workers=num_workers,
use_gpu=True,
resources_per_worker={"CPU": 8, "GPU": 2},
accelerator_type="T4",
)
import tempfile
import mlflow
import numpy as np
from ray.train.torch import TorchTrainer
def train_epoch(ds, batch_size, model, num_classes, loss_fn, optimizer):
model.train()
loss = 0.0
ds_generator = ds.iter_torch_batches(batch_size=batch_size, collate_fn=collate_fn)
for i, batch in enumerate(ds_generator):
optimizer.zero_grad() # Reset gradients.
z = model(batch) # Forward pass.
targets = F.one_hot(batch["label"], num_classes=num_classes).float()
J = loss_fn(z, targets) # Define loss.
J.backward() # Backward pass.
optimizer.step() # Update weights.
loss += (J.detach().item() - loss) / (i + 1) # Cumulative loss
return loss
def eval_epoch(ds, batch_size, model, num_classes, loss_fn):
model.eval()
loss = 0.0
y_trues, y_preds = [], []
ds_generator = ds.iter_torch_batches(batch_size=batch_size, collate_fn=collate_fn)
with torch.inference_mode():
for i, batch in enumerate(ds_generator):
z = model(batch)
targets = F.one_hot(
batch["label"], num_classes=num_classes
).float() # one-hot (for loss_fn)
J = loss_fn(z, targets).item()
loss += (J - loss) / (i + 1)
y_trues.extend(batch["label"].cpu().numpy())
y_preds.extend(torch.argmax(z, dim=1).cpu().numpy())
return loss, np.vstack(y_trues), np.vstack(y_preds)
def train_loop_per_worker(config):
# Hyperparameters.
model_registry = config["model_registry"]
experiment_name = config["experiment_name"]
embedding_dim = config["embedding_dim"]
hidden_dim = config["hidden_dim"]
dropout_p = config["dropout_p"]
lr = config["lr"]
lr_factor = config["lr_factor"]
lr_patience = config["lr_patience"]
num_epochs = config["num_epochs"]
batch_size = config["batch_size"]
num_classes = config["num_classes"]
# Experiment tracking.
if ray.train.get_context().get_world_rank() == 0:
mlflow.set_tracking_uri(f"file:{model_registry}")
mlflow.set_experiment(experiment_name)
mlflow.start_run()
mlflow.log_params(config)
# Datasets.
train_ds = ray.train.get_dataset_shard("train")
val_ds = ray.train.get_dataset_shard("val")
# Model.
model = ClassificationModel(
embedding_dim=embedding_dim,
hidden_dim=hidden_dim,
dropout_p=dropout_p,
num_classes=num_classes,
)
model = ray.train.torch.prepare_model(model)
# Training components.
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode="min",
factor=lr_factor,
patience=lr_patience,
)
# Training.
best_val_loss = float("inf")
for epoch in range(num_epochs):
# Steps
train_loss = train_epoch(
train_ds, batch_size, model, num_classes, loss_fn, optimizer
)
val_loss, _, _ = eval_epoch(val_ds, batch_size, model, num_classes, loss_fn)
scheduler.step(val_loss)
# Checkpoint (metrics, preprocessor and model artifacts).
with tempfile.TemporaryDirectory() as dp:
model.module.save(dp=dp)
metrics = dict(
lr=optimizer.param_groups[0]["lr"],
train_loss=train_loss,
val_loss=val_loss,
)
with open(os.path.join(dp, "class_to_label.json"), "w") as fp:
json.dump(config["class_to_label"], fp, indent=4)
if ray.train.get_context().get_world_rank() == 0: # only on main worker 0
mlflow.log_metrics(metrics, step=epoch)
if val_loss < best_val_loss:
best_val_loss = val_loss
mlflow.log_artifacts(dp)
# End experiment tracking.
if ray.train.get_context().get_world_rank() == 0:
mlflow.end_run()
Minimal change to your training code
Notice that there isn’t much new Ray Train code on top of the base PyTorch code. You specified how you want to scale out the training workload, load the Ray datasets, and then checkpoint on the main worker node and that’s it. See these guides (PyTorch, PyTorch Lightning, Hugging Face Transformers) to see the minimal change in code needed to distribute your training workloads. See this extensive list of Ray Train user guides.
# Load preprocessed datasets.
preprocessed_train_ds = ray.data.read_parquet(preprocessed_train_path)
preprocessed_val_ds = ray.data.read_parquet(preprocessed_val_path)
# Trainer.
train_loop_config["class_to_label"] = preprocessor.class_to_label
train_loop_config["num_classes"] = len(preprocessor.class_to_label)
trainer = TorchTrainer(
train_loop_per_worker=train_loop_per_worker,
train_loop_config=train_loop_config,
scaling_config=scaling_config,
datasets={"train": preprocessed_train_ds, "val": preprocessed_val_ds},
)
# Train.
results = trainer.fit()
(autoscaler +3m40s) [autoscaler] [4xT4:48CPU-192GB] Attempting to add 1 node to the cluster (increasing from 1 to 2).
(autoscaler +3m40s) [autoscaler] [4xT4:48CPU-192GB|g4dn.12xlarge] [us-west-2a] [on-demand] Launched 1 instance.
(autoscaler +3m45s) [autoscaler] Cluster upscaled to {112 CPU, 8 GPU}.
(autoscaler +4m30s) [autoscaler] Cluster upscaled to {160 CPU, 12 GPU}.