Ray Serve#
Ray Serve is a highly scalable and flexible model serving library for building online inference APIs that allows you to:
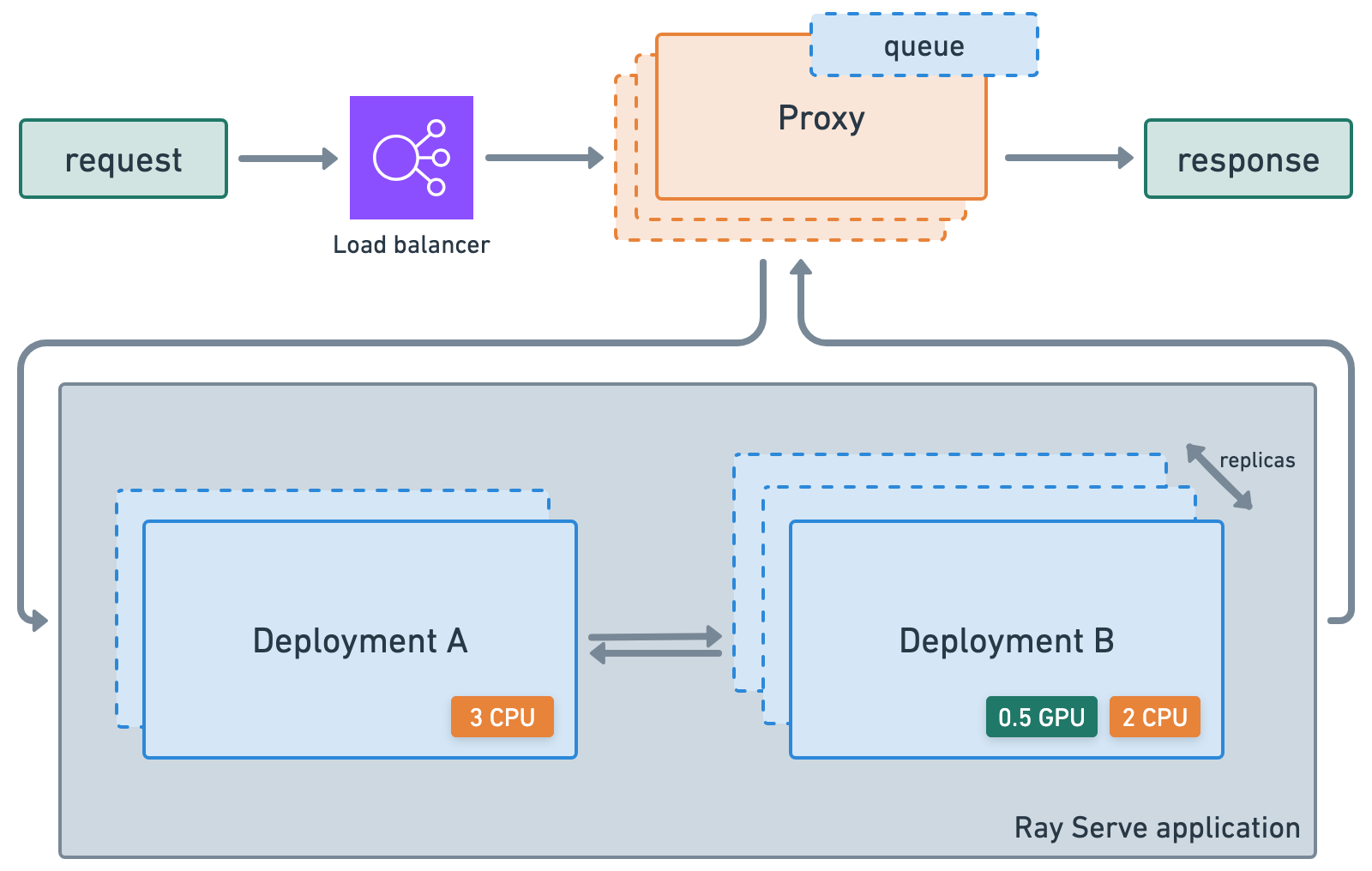
Wrap models and business logic as separate serve deployments and connect them together (pipeline, ensemble, etc.)
Avoid one large service that’s network and compute bounded and an inefficient use of resources.
Utilize fractional heterogeneous resources, which isn’t possible with SageMaker, Vertex, KServe, etc., and horizontally scale with
num_replicas.autoscale up and down based on traffic.
Integrate with FastAPI and HTTP.
Set up a gRPC service to build distributed systems and microservices.
Enable dynamic batching based on batch size, time, etc.
Access a suite of utilities for serving LLMs that are inference-engine agnostic and have batteries-included support for LLM-specific features such as multi-LoRA support
🔥 RayTurbo Serve on Anyscale has more functionality on top of Ray Serve:
fast autoscaling and model loading to get services up and running even faster with 5x improvements even for LLMs.
54% higher QPS and up-to 3x streaming tokens per second for high traffic serving use-cases with no proxy bottlenecks.
replica compaction into fewer nodes where possible to reduce resource fragmentation and improve hardware utilization.
zero-downtime incremental rollouts so your service is never interrupted.
different environments for each service in a multi-serve application.
multi availability-zone aware scheduling of Ray Serve replicas to provide higher redundancy to availability zone failures.