Ray Serve LLM + Anyscale Architecture#
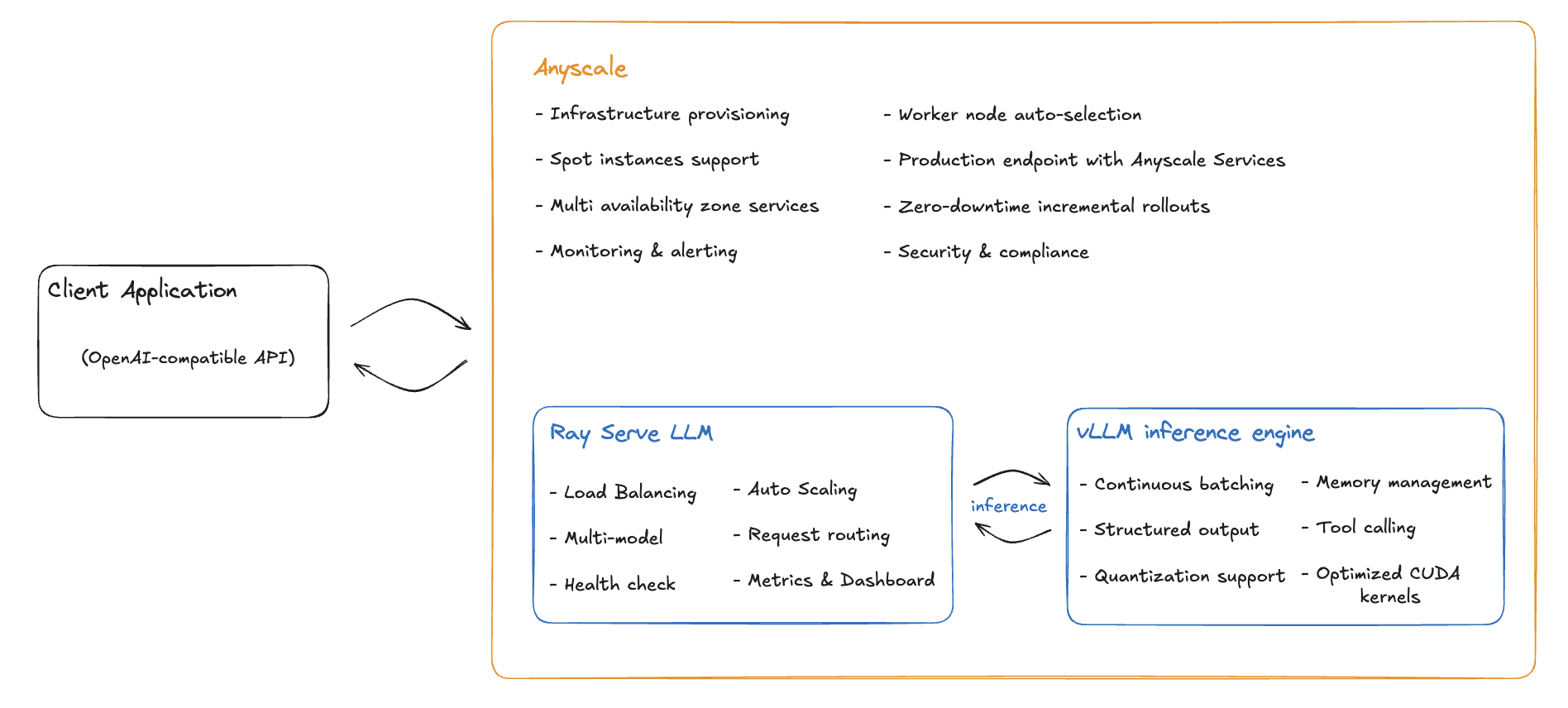
Here is a diagram of how Ray Serve LLM + Anyscale provides a production-grade solution to your LLM deployment:
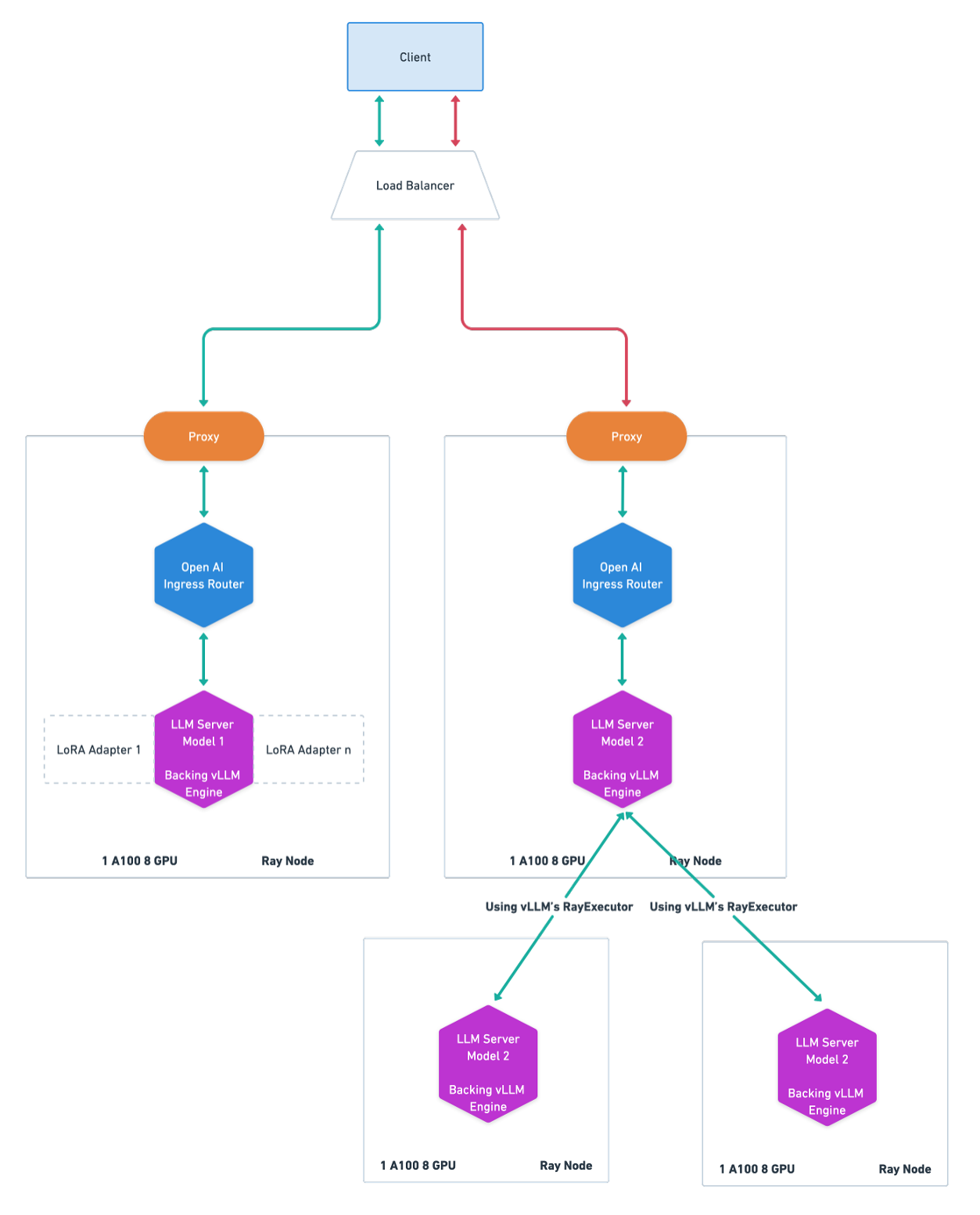
Notes:
The above shows only one replica per model, but Ray Serve can easily scale to deploying multiple replicas.
Ray Serve LLM + Anyscale provides a production-grade solution through three integrated components:
1. Ray Serve for Orchestration#
Ray Serve handles the orchestration and scaling of your LLM deployment:
Automatic scaling: Adds/removes model replicas based on traffic
Load balancing: Distributes requests across available replicas
Unified multi-model deployment: Deploy and manage multiple models
OpenAI-compatible API: Drop-in replacement for OpenAI clients
Here is a diagram of how Ray Serve LLM interact with a client’s request
2. vLLM as the inference engine#
LLM inference is a non-trivial problem that requires tuning low-level hardware use and high-level algorithms. An inference engine abstracts this complexity and optimizes model execution. Ray Serve LLM natively integrates vLLM as its inference engine for several reasons:
Fast GPU computation with CUDA kernels specifically optimized for LLM inference.
Continuous batching: Continuously schedule tokens to be processed to maximize GPU utilization.
Smart memory use: Optimize memory usage with state-of-the-art algorithms like PagedAttention
Ray Serve LLM gives you high flexibility on how to configure your vLLM engine (more on that later).
3. Anyscale for Infrastructure#
Anyscale provides managed infrastructure and enterprise features:
Managed infrastructure: Optimized Ray clusters in your cloud
Cost optimization: Pay-as-you-go, scale-to-zero
Enterprise security: VPC, SSO, audit logs
Seamless scaling: Handle traffic spikes automatically