Ray Data#
Ray Data not only makes it extremely easy to distribute workloads but also ensures that they with:
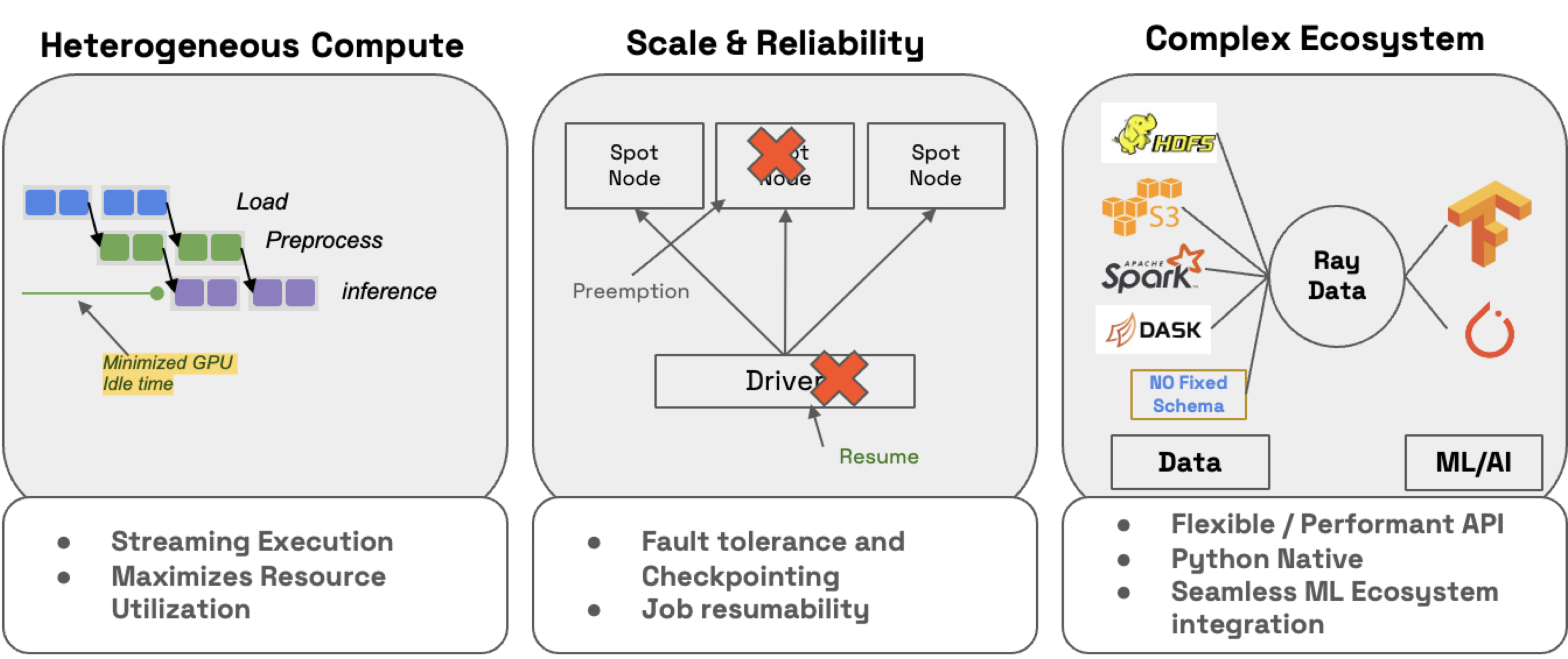
efficiency: minimize CPU/GPU idle time with heterogeneous resource scheduling.
scalability: streaming execution to petabyte-scale datasets, especially when working with LLMs
reliability by checkpointing processes, especially when running workloads on spot instances with on-demand fallback.
flexibility: connect to data from any source, apply transformations, and save to any format or location for your next workload.
🔥 RayTurbo Data has more functionality on top of Ray Data:
accelerated metadata fetching to improve reading from large datasets (start processes earlier).
optimized autoscaling where actor pools are scaled up faster, start jobs before entire cluster is ready, etc.
high reliability where entire fails jobs (even on spot instances), like head node, cluster, uncaptured exceptions, etc., can resume from checkpoints. OSS Ray can only recover from worker node failures.